
Business Technology Architecture Body of Knowledge
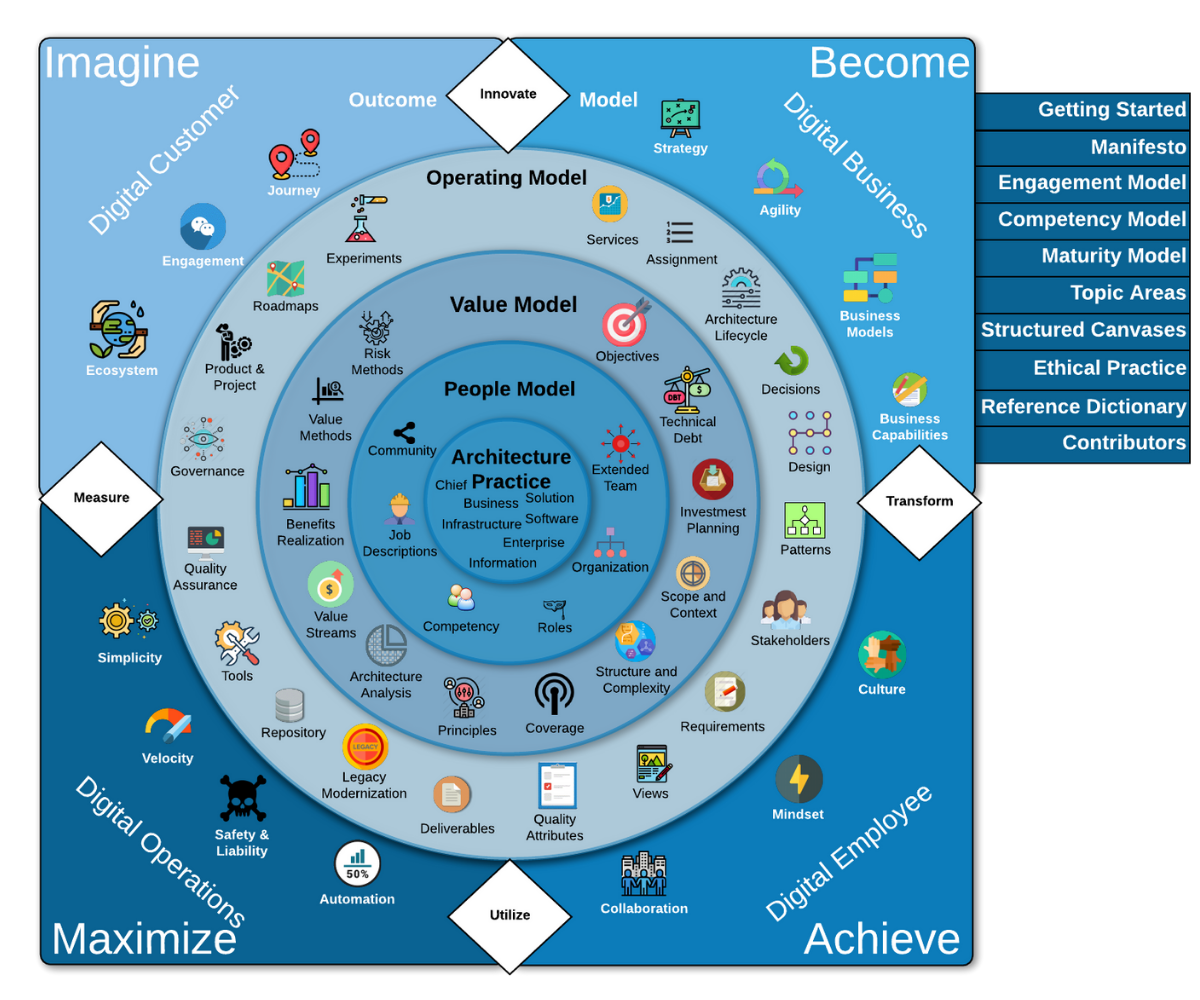

Getting Started
The Business Technology Architecture Body of Knowledge (Btabok) is a free public archive of IT architecture best practices, skills, and knowledge developed from the experience of individual and corporate members of Iasa, the world’s largest IT architecture professional organization.
BTABoK provides the tools and resources needed by individuals and organizations to set industry standards for professional career development and well as hiring practices and incorporation of IT architects into established or developing institutions.
Whats inside BTABoK?
Defining the IT Architect Profession – What is an IT architect? We provide industry reference models for architects skills and competencies backed by international certifications.
Utilization & Engagement of IT Architects – How are IT architects utilized within organizations and what are the interaction models between them and their clients or employers?
Career Pathway – Describes the standard career path of an architect including specializations and career achievement milestones.
What you should know before you read the BoK
Overview
The Business Technology Architecture Body of Knowledge (BTABoK) has been developed from the experience and practice of individual and corporate members.
In addition to being a reference, a knowledge base and a list of professional capabilities, the BTABoK is meant to be essential in implementing an architecture practice within an organization, without significant changes to other standards, roles, practices and lifecycles. An architecture practice provides high levels of value in both business and technical strategy, and that value can be measured as a contribution to the organization. Architecture is appropriate and essential for extremely small businesses, as well as, the largest businesses in the world, including non-profit, government, and defense.
The BTABoK is first and foremost intended for individual practicing architects, though it does include significant portions dedicated to organizational excellence. It is meant as a people framework as opposed to a process, methodology or standard. It is meant to be the living body of knowledge for the practice of an architect attempting to fulfill their duty to their customer or employer. While Iasa includes corporate examples and concerns, the BTABoK must be useful by the independent practitioner and must assume that a single architect is as important as a group of architects. In addition, the BTABoK must be consistent and useful at any degree of scale, regardless of the number of architects involved in the endeavor, whether that be the delivery of a global fortune 100 business strategy or the delivery of a single solution for a small business.
The BTABoK is inclusive of all specializations, sub-specializations and career levels of the architect profession. Although the title includes the terms information technology, the content has been written by keeping business, enterprise, solutions, software, information and infrastructure architects and their derivations in mind. Practitioners from each of these specializations continue to help in the development and maintenance of the body of knowledge.
What is Architecture?
Architecture at Iasa is the practice of business, organization or client gain through the application of technology strategy. It is the art and science of designing and delivering valuable technology strategy. The BoK describes this as business technology strategy, which forms the primary pillar of the 5 pillars of architecture skill. Other words Iasa uses to describe this are innovation, ideation, and value management. At its core, the BTABoK describes how to create a professional person or group of professionals who can consistently find new applications of technology to generate positive outcomes for their client or employer.
The BTABoK provides a reference point for a particular type of architect and may not fit all titled or non-titled definitions. Iasa has long been aware that some architects focus on the development of models as their primary concern, using designs to aid in governance, understanding a business or optimization of an information technology group. Some architects claim they are designing or engineering an entire enterprise. All of these activities are beneficial. However, the BTABoK is focused on developing a profession of architect where practitioners fulfill all or most of the following throughout their career:
- Retain depth in technical skill as well as business skill.
- Able to successfully work with both business and technical staff.
- Develop their own or others business cases based on technology driven innovation.
- Retain the ability to deliver projects on those business cases, generally at increasing levels of complexity.
- Deliver business projects more successfully based on outcomes than others.
- Are committed to the identification of repeatability in business technology outcomes.
- Are as much an artists as scientists.
Use the links below to access the body of knowledge content
Why ITABoK
WHY DID WE CREATE THE BTABOK
Giving Feedback
HOW YOUR COMMENTS CAN HELP IMPROVE BTABOK
What is Architecture
UNDERSTANDING ARCHITECTURE
Additional Resources
Contact Iasa
If you would like to contribute to the BTAbok, please send us an email to contactus@iasaglobal.org


