
By John Piekos, VoltDB, Vice President, Engineering
Sizing an in-memory database does not follow conventional database sizing rules. For traditional databases, you buy a decent server machine, likely one with many CPU cores and reasonable memory, and then focus on application IOPS (I/O Operations per Second). If you are really going to stress the database, you must choose disks that can support the I/O needs of your application, today and in the future.
Because these systems often use many disks to achieve high I/O performance, capacity is usually an afterthought. With in-memory databases, throw out everything you know about sizing databases. Performance is now the afterthought, but capacity must be carefully considered.
To size an in-memory clustered database application you must consider the following factors:
- First, compute the size of the data your application expects to host. This means computing the size of all rows in all tables. And also computing the size of all table indexes. VoltDB provides an easy-to-use interactive sizing tool in our application catalog report, described later in this post.
- If you want a highly available database cluster, all data must be stored redundantly. You’ll need to multiply your logical data size by the replication factor to understand your memory requirements. For example, if you have 100GB of table and index data, and you want your database to be able to withstand losing one of the nodes in the cluster, you will want each datum to be stored twice, and on two different physical machines. This means that you need to size the data requirement of your database to be 200GB (100GB of data X 2 copies of the data).
- Allow for some extra memory, perhaps an additional 25%, for database and operating system overhead. VoltDB uses extra memory for storing intermediate results, maintaining an undo log, caching SQL plans and buffering network data. Note that on a machine with 4GB, you’ll want to leave a larger fraction of memory free than on a machine with 256GB.
This tallied memory total can now help you decide how many machines your system requires. Note at no time did we need to determine how much CPU we required, or how many IOPS were needed. Because you are sizing your database based on data, memory size is the most important calculation you will likely use. Generally speaking, in-memory databases like VoltDB operate so fast that CPU utilization is not a problem – there is plenty of headroom for growth. As for disk I/O, most in-memory systems use sequential logs on disk, eschewing costly random I/O. With this reduced dependency on disk performance, VoltDB can achieve tremendous throughput, even on commodity spinning disks.
Often, you’ll be faced with a choice between many machines with less memory per machine or a small number of high-memory machines. There are lots of reasons to lean one way or the other. For example, you should try to run with at least three nodes if availability or redundancy is a concern. Additionally, some administrator operations run faster with less per-machine data. At some point, however, too many nodes can be a management hassle. Most VoltDB users run with 3 to 30 nodes per cluster for these reasons.
Planning for Data Capacity and Growth
Sizing VoltDB databases is fairly straightforward. Once you have settled on your application’s database schema, point your web browser to the database Catalog Report and choose the “Size Worksheet”, found at this URL: http://localhost:8080/#z (note the database must be running).
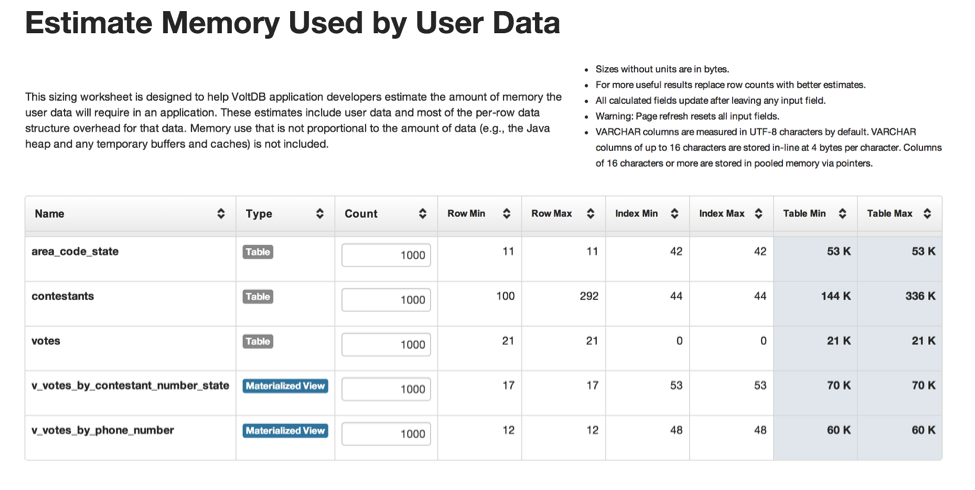
This sizing worksheet is automatically built from your application’s schema. It allows you to enter your expected number of rows for each table and then computes the amount of memory required for the database cluster as a whole.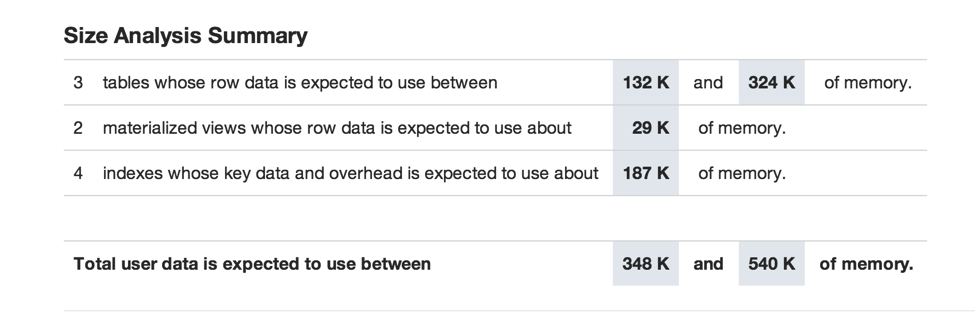
Note that the footprint of your database is the size of the number of rows as well as the size of all indexes and materialized views. You must also leave additional memory for the operating system. Note that this assumes VoltDB is the only active application on these machines. If you plan on sharing the machines with other applications (something we do not recommend), your memory requirements will naturally be larger.
Expanding your Database Capacity
A well-designed IT environment will monitor the performance and capacity of the applications running the business. Because VoltDB processes transactions incredibly fast, it is often the case that there is plenty of transaction throughput headroom, and lots of extra CPU cycles, available. Monitoring the memory usage of the database cluster becomes much more important. VoltDB provides monitoring interfaces, as well as Nagios and New Relic plug-ins, that make monitoring memory usage easy. These tools allow you to define capacity alerts, in much the same way you would define disk space usage alerts for legacy database systems. Should your in-memory database memory usage grow to a high level, signaling a capacity limit alert, it may be time to add more storage capacity to your database.
With VoltDB, adding capacity is easy: simply add more nodes. VoltDB supports adding nodes to a running cluster without interrupting ongoing operations or sacrificing ACID transactional guarantees.
If you do not wish to add more nodes to your database cluster, doing a rolling memory upgrade of machines in a redundant VoltDB cluster is an alternative. Since VoltDB uses active replication within a cluster, removing and replacing a node can be done transparently to a user’s application with no data loss and often-unnoticeable performance impact.
In-Memory Database provisioning… A New Way of Thinking
If you are provisioning and rolling out a new application using an in-memory database you will have to shift your thinking about how you size your deployment. With all data residing in memory you will need to provision enough memory in your database cluster to hold all of your data, with a bit more memory for regular operating system operations.
Disks are only used for durability, and most in-memory systems like VoltDB work great with commodity hardware, disks included. Sizing for IOPS is a thing of the past!
For more information on VoltDB check out our webinar with IBM:
The Key to Unlocking the Economic Value of Fast Data in the Cloud.
Wednesday, 8/6 at 11:30am ET
